
Friday, 17 February 2017
Thursday, 16 February 2017
Session 6: Plotting addresses on Google Maps using R and R Google Maps
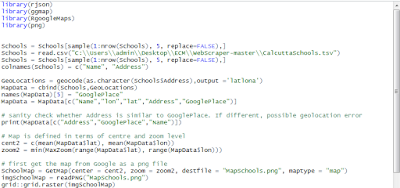
Plotting Addresses on Google Maps using R and R GoogleMaps
In an earlier post, we had shown how locations as defined by addresses could be plotted on Google Maps but the process was rather complicated. First, the geocoding had to be done separately and secondly a lot of messy Javascript had to be coded by hand. Finally the map that was produced could only be viewed with an internet connection.







Wednesday, 1 February 2017
Session 6 :Visualization : Using R for Maps of India - state, district, taluka level maps
Using R for Maps of India - state, district, taluka level maps
Displaying spatial data on maps is always interesting but most Visualisation tools do not offer facilities to create maps of India, especially at the state and lower levels. In this post, we will show how such maps can be made.The base data for such maps, the "polygons" that define the country, the states, the districts and even the talukas ( or sub-divisions) is available from an organisation called Global Administrative Areas or gadm.org. Country level files for almost all countries are available in a variety of formats including R and these are at three different levels. For India, these files can be downloaded as IND_admN.RData where N = 1,2,3. These will form the raw data from which we will create our maps.




Monday, 30 January 2017
Session 7 :Visualization : Python /Seaborne Multiple Linear Regression
Seaborn: statistical data visualization
Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing attractive statistical graphics.
Seaborn is a library for making attractive and informative statistical graphics in Python. It is built on top of matplotlib and tightly integrated with the PyData stack, including support for numpy and pandas data structures and statistical routines from scipy and statsmodels.
Some of the Features that seaborn offer are
- Several built-in themes that improve on the default matplotlib aesthetics
- Tools for choosing color palettes to make beautiful plots that reveal patterns in your data
- Functions for visualizing univariate and bivariate distributions or for comparing them between subsets of data
- Tools that fit and visualize linear regression models for different kinds of independent and dependent variables
- Functions that visualize matrices of data and use clustering algorithms to discover structure in those matrices
- A function to plot statistical timeseries data with flexible estimation and representation of uncertainty around the estimate
- High-level abstractions for structuring grids of plots that let you easily build complex visualizations
Seaborn aims to make visualization a central part of exploring and understanding data. The plotting functions operate on dataframes and arrays containing a whole dataset and internally perform the necessary aggregation and statistical model-fitting to produce informative plots. If matplotlib “tries to make easy things easy and hard things possible”, seaborn tries to make a well-defined set of hard things easy
Grouped barplots
import seaborn as sns sns.set(style="whitegrid") # Load the example Titanic dataset titanic = sns.load_dataset("titanic") # Draw a nested barplot to show survival for class and sex g = sns.factorplot(x="class", y="survived", hue="sex", data=titanic, size=6, kind="bar", palette="muted") g.despine(left=True) g.set_ylabels("survival probability")

Codes for Violinplot
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="whitegrid")
# Load the example dataset of brain network correlations
df = sns.load_dataset("brain_networks", header=[0, 1, 2], index_col=0)
# Pull out a specific subset of networks
used_networks = [1, 3, 4, 5, 6, 7, 8, 11, 12, 13, 16, 17]
used_columns = (df.columns.get_level_values("network")
.astype(int)
.isin(used_networks))
df = df.loc[:, used_columns]
# Compute the correlation matrix and average over networks
corr_df = df.corr().groupby(level="network").mean()
corr_df.index = corr_df.index.astype(int)
corr_df = corr_df.sort_index().T
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 6))
# Draw a violinplot with a narrower bandwidth than the default
sns.violinplot(data=corr_df, palette="Set3", bw=.2, cut=1, linewidth=1)
# Finalize the figure
ax.set(ylim=(-.7, 1.05))
sns.despine(left=True, bottom=True)

Thursday, 26 January 2017
Wednesday, 25 January 2017
Session 4 - Creating a dashboard Part I
Creating a Dashboard - Part 1
When you have a lot of data to be shown on a page, it makes sense to give the viewer an opportunity to filter some of the data so that he or she gets a cleaner view. In this case, we will first draw a rather clumsy Column Chart and then in the next section. The data for the chart is drawn from this spreadsheet. The chart shown below can also be seen in this regular HTML page.
Note how we have specified
- the Google Docs spreadsheet : https://docs.google.com/a/yantrajaal.com/spreadsheet/ccc?key=0AhEX55Pfl1eedExUbS1xNzBuQVAyNDJTeG1weFQxbXc
- the sheet : sheet=MilkProduction
- range : range=B2:H37
- headers : headers=1
- columns : query.setQuery('select B,E,F');
- chart type : var chartMQ = new google.visualization.ColumnChart(document.getElementById('chart_divMQ'))
Basic Column Chart Showing All Data
Monday, 23 January 2017
Session 6 -Plotting Cities in a Map
Plotting Cities on a Map along with Data
In the code please observe the following points
- The spreadsheet doc is identified as https://docs.google.com/a/yantrajaal.com/spreadsheet/ccc?key=0AhEX55Pfl1eedE5mUHN4QVRLNzdldEpwZnAyNy1abUE
- The sheets as identified by sheet=CityWise2
- The range is identified by range=B2:M23
- The columns being selected are identified by query.setQuery('select B,D,E');
- The region in the map is 'IN' that is India
- The displayMode is "markers" .. which means towns and cities, had this been region we would have got full states.
Session 4 : Creating a Dashboard - Part II
Creating a Dashboard - Part II
Here we take the same data used in the previous post and convert it into a dashboard. We have replaced the chart with a chart wrapper. Added three filters. Added a dashboard component and bound the three filters to the chart wrapper. You can see the result both in this blog as well as on this regular HTML page.
The Dashboard on this blog
Session 4 : The best of R and Google Charts
Data: StateMilk • Chart ID: GeoChartID9147ed26b9d • googleVis-0.6.2
R version 3.2.5 (2016-04-14) • Google Terms of Use • Documentation and Data Policy
R version 3.2.5 (2016-04-14) • Google Terms of Use • Documentation and Data Policy
Session 4:Visualisation:Specifying Range of Data and Selecting Columns:Google charts with Google Docs data
3 Specifying Range of Data and Selecting Columns : Google Charts with Google Docs data
In the previous post, we had described how to create a basic Google Chart from data stored in a Google Doc spreadsheet. In that example, the data was picked up from the default first sheet of the spreadsheet and the data was located in the top left corner. In reality, the data could be stored in any of the other sheets and could be located in any portion of the sheet.
In this example, the Google Docs spreadsheet, has four sheets. For the purpose of drawing our chart we would like to specify that
In this example, the Google Docs spreadsheet, has four sheets. For the purpose of drawing our chart we would like to specify that
- Data to be picked up from sheet named "Demo3"
- Within this sheet, from the range C3:I23
- Within this range from the columns C, D, G, H
- Given the nature of the data we would like to multiply column G by 1000 before it is plotted
Friday, 13 January 2017
Data Visualization in R
BASIC VISUALIZATIONS
- Basic graphs in R can be created quite easily. The plot command is the command to note.
- It takes in many parameters from x axis data , y axis data, x axis labels, y axis labels, color and title. To create line graphs, simply use the parameter, type=l.
- If you want a boxplot, you can use the word boxplot, and for barplot use the barplot function.
Basic Visualization which we are going to perform here
- Histogram
- Bar / Line Chart
- Box plot
- Scatter plo
1. Histogram
Histogram is basically a plot that breaks the data into bins (or breaks) and shows frequency distribution of these bins. You can change the breaks also and see the effect it has data visualization in terms of understandability.
Let me give you an example.
Note: We have used par(mfrow=c(2,5)) command to fit multiple graphs in same page for sake of clarity( see the code below).
The following commands show this in a better way. In the code below, the main option sets the Title of Graph and the col option calls in the color pallete from RColorBrewer to set the colors.
library(RColorBrewer)
data(VADeaths)
par(mfrow=c(2,3))
hist(VADeaths,breaks=10, col=brewer.pal(3,"Set3"),main="Set3 3 colors")
hist(VADeaths,breaks=3 ,col=brewer.pal(3,"Set2"),main="Set2 3 colors")
hist(VADeaths,breaks=7, col=brewer.pal(3,"Set1"),main="Set1 3 colors")
hist(VADeaths,,breaks= 2, col=brewer.pal(8,"Set3"),main="Set3 8 colors")
hist(VADeaths,col=brewer.pal(8,"Greys"),main="Greys 8 colors")
hist(VADeaths,col=brewer.pal(8,"Greens"),main="Greens 8 colors")

2. Bar/ Line Chart
Line Chart
Below is the line chart showing the increase in air passengers over given time period. Line Charts are commonly preferred when we are to analyse a trend spread over a time period. Furthermore, line plot is also suitable to plots where we need to compare relative changes in quantities across some variable (like time). Below is the code:
plot(AirPassengers,type="l") #Simple Line Plot
plot(AirPassengers,type="l") #Simple Line Plot
 Bar Chart
Bar Chart
Bar Plots are suitable for showing comparison between cumulative totals across several groups. Stacked Plots are used for bar plots for various categories. Here’s the code:
barplot(iris$Sepal.Length,col = brewer.pal(3,"Set1"))
barplot(table(iris$Species,iris$Sepal.Length),col = brewer.pal(3,"Set1")) #Stacked Plot



3. Box Plot ( including group-by option )
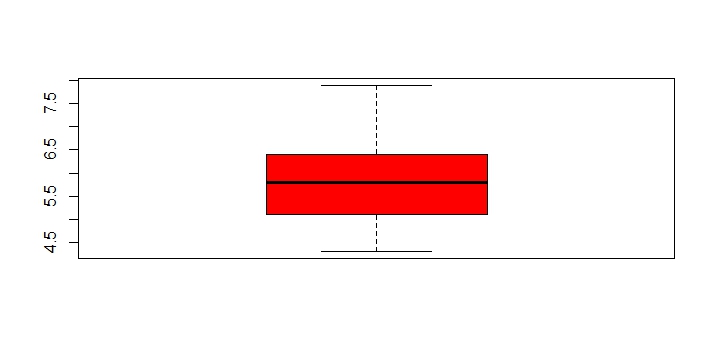
Box Plot shows 5 statistically significant numbers- the minimum, the 25th percentile, the median, the 75th percentile and the maximum. It is thus useful for visualizing the spread of the data is and deriving inferences accordingly. Here’s the basic code:boxplot(iris$Petal.Length~iris$Species) #Creating Box Plot between two variableLet’s understand the code below:In the example below, I have made 4 graphs in one screen. By using the ~ sign, I can visualize how the spread (of Sepal Length) is across various categories ( of Species). In the last two graphs I have shown the example of color palettes. A color palette is a group of colors that is used to make the graph more appealing and helping create visual distinctions in the data.data(iris)
par(mfrow=c(2,2))
boxplot(iris$Sepal.Length,col="red")
boxplot(iris$Sepal.Length~iris$Species,col="red")
boxplot(iris$Sepal.Length~iris$Species,col=heat.colors(3))
boxplot(iris$Sepal.Length~iris$Species,col=topo.colors(3))
4. Scatter Plot (including 3D and other features)
Scatter plots help in visualizing data easily and for simple data inspection. Here’s the code for simple scatter and multivariate scatter plot:
plot(x=iris$Petal.Length) #Simple Scatter Plot
plot(x=iris$Petal.Length,y=iris$Species) #Multivariate Scatter PlotScatter Plot Matrix can help visualize multiple variables across each other.plot(iris,col=brewer.pal(3,"Set1"))





Thursday, 12 January 2017
DETAILED INTRODUCTION -GGPLOT2
Detailed Introduction
DETAILED INTRODUCTION
About the ggplot2 Package
Introduction "ggplot2 is an R package for producing statistical, or data, graphics, but it is unlike most other graphics packages because it has a deep underlying grammar. This grammar, based on the Grammar of Graphics (Wilkinson, 2005), is composed of a set of independent components that can be composed in many different ways. [..] Plots can be built up iteratively and edited later. A carefuly chosen set of defaults means that most of the time you can produce a publication-quality graphic in seconds, but if you do have speical formatting requirements, a comprehensive theming system makes it easy to do what you want. [..] ggplot2 is designed to work in a layered fashion, starting with a layer showing the raw data then adding layers of annotation and statistical summaries.
ggplot2,
First We look into the header of Diamonds and Mtcars data
head(diamonds)
head(mtcars)


qplot histogram
qplot(clarity, data=diamonds, fill=cut, geom="bar")
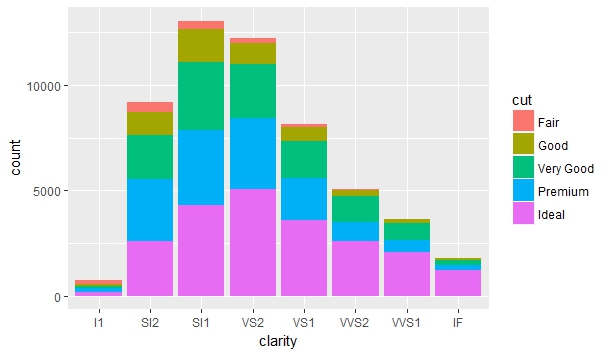
ggplot(diamonds, aes(clarity, fill=cut)) + geom_bar()

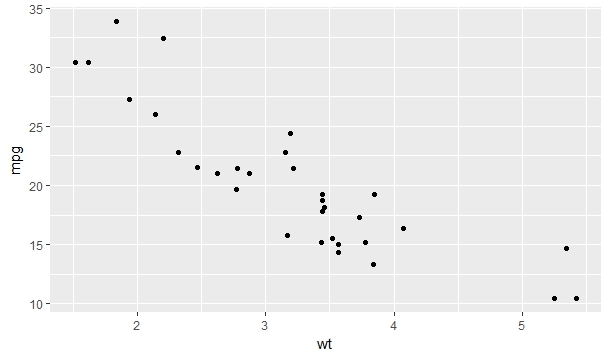
Scatterplot
qplot(wt, mpg, data=mtcars)
 Transform input data with functions
Transform input data with functions
qplot(log(wt), mpg - 10, data=mtcars)

Add aesthetic mapping (hint: how does mapping work)
qplot(wt, mpg, data=mtcars, color=qsec)

Change size of points (hint: color/colour, hint: set aesthetic/mapping)
qplot(wt, mpg, data=mtcars, color=qsec, size=3)
qplot(wt, mpg, data=mtcars, colour=qsec, size=I(3))

Use alpha blending
qplot(wt, mpg, data=mtcars, alpha=qsec)

Continuous scale vs. discrete scale
head(mtcars)
qplot(wt, mpg, data=mtcars, colour=cyl)
levels(mtcars$cyl)
qplot(wt, mpg, data=mtcars, colour=factor(cyl))

Continuous scale vs. Discrete scale
head(mtcars)
qplot(wt, mpg, data=mtcars, colour=cyl)
levels(mtcars$cyl)
qplot(wt, mpg, data=mtcars, colour=factor(cyl))


Use different aesthetic mappings
qplot(wt, mpg, data=mtcars, shape=factor(cyl))
qplot(wt, mpg, data=mtcars, size=qsec)


Combine mappings (hint: hollow points, geom-concept, legend combination)
qplot(wt, mpg, data=mtcars, size=qsec, color=factor(carb))
qplot(wt, mpg, data=mtcars, size=qsec, color=factor(carb), shape=I(1))
qplot(wt, mpg, data=mtcars, size=qsec, shape=factor(cyl), geom="point")
qplot(wt, mpg, data=mtcars, size=factor(cyl), geom="point")




Bar-plot
qplot(factor(cyl), data=mtcars, geom="bar")

Flip plot by 90°
qplot(factor(cyl), data=mtcars, geom="bar") + coord_flip()

Difference between fill/color bars
qplot(factor(cyl), data=mtcars, geom="bar", fill=factor(cyl))
qplot(factor(cyl), data=mtcars, geom="bar", colour=factor(cyl))


Fill by variable
qplot(factor(cyl), data=mtcars, geom="bar", fill=factor(gear))


Use different display of bars (stacked, dodged, identity)
head(diamonds)
qplot(clarity, data=diamonds, geom="bar", fill=cut, position="stack")
qplot(clarity, data=diamonds, geom="bar", fill=cut, position="dodge")
qplot(clarity, data=diamonds, geom="bar", fill=cut, position="fill")
qplot(clarity, data=diamonds, geom="bar", fill=cut, position="identity")
qplot(clarity, data=diamonds, geom="freqpoly", group=cut, colour=cut, position="identity")
qplot(clarity, data=diamonds, geom="freqpoly", group=cut, colour=cut, position="stack")


Subscribe to:
Comments (Atom)